
REPORT
TEST MATERIAL FORMAT AND AVAILABILITY
January 1999
Report for the TMR PHYSTA project
“Principled Hybrid systems: Theory and Applications”
Research contract FMRX-CT97-0098 (DG 12 – BDCN)
Contents
1. AIMS, PRINCIPLES AND PREVIEW 4
1.1 The theory of emotion 4
1.2 Samples of emotional behaviour 5
1.3 Signal and interpretation streams 5
1.4 Overview and state of progress 6
2. PRE-EXISTING MATERIAL 8
2.1 Sources dealing with the study of human emotion 8
2.2 Faces: static images 9
2.3 Faces: videos 12
2.4 Speech 13
2.5 Speech and Video 15
2.6 Overview 16
3. OBTAINING STIMULUS SEQUENCES 17
3.1 Context free simulations 17
3.2 Reading 17
3.3 Prompting 18
3.4 Games 19
3.5 Broadcast 20
3.6 Social facilitation 20
3.7 Overview 21
4. ASSIGNING INTERPRETATIONS 22
4.1 'Cause' and 'effect' assignments 22
4.2 Validation 22
4.3 Categorical 23
4.4 Dimensional 24
4.5 World models 25
4.6 Units of analysis 26
4.7 Uniqueness and uncertainty 27
5. FORMATS UNDER DEVELOPMENT 28
5.1 Socially facilitated emotive exchanges 28
5.2 Feeltrace 28
5.3 Feeltrace applied to emotive exchanges: preliminary findings 31
6. ARCHIVE FORMAT 34
6.1 Core recordings 34
6.2 Supplementary recordings 34
6.3 Recording 35
6.4 Digitisation 35
6.5 Continuous descriptors 36
6.6 Unit summary files 36
7. CONCLUSION 37
APPENDIX 38
1. AIMS, PRINCIPLES AND PREVIEW
This report is part of the PHYSTA project, which aims to develop an artificial emotion decoding system. The system will use two types of input, visual (specifically facial expression) and acoustic (specifically non-verbal aspects of the speech signal).
PHYSTA will use hybrid technology, i.e. a combination of classical (AI) computing and neural nets. Broadly speaking, the classical component allows for the use of known procedures and logical operations which are suited to language processing. The neural net component allows for learning at various levels, for instance the weights that should be attached to various inputs, adjacencies, and probabilities of particular events given certain information.
Assembling appropriate training and test material is fundamental to the project. It provides the raw information on which the neural net component's processing will be based. This report examines the problem of providing appropriate material.
The report is underpinned by theory and evidence about emotion that was reviewed in a previous report. Three main types of issue are directly relevant, and are summarised here.
1.1 The theory of emotion
The fundamental point here is that the most familiar type of theory is not the only candidate. Others exist, and they suggest different approaches to the task of detecting emotion.
The classical approach, which remains the best known to scientists and engineers, reflects two main ideas about emotion - that everyday emotion is produced by combining a few primary emotions, and that emotion has particularly close connections with biology. Accepting that kind of outlook would have major implications for PHYSTA in general and for the collection of test material in particular, because it suggests that the project's priority should be to analyse situations involving the primary emotions, and that the measures to be taken should relate as directly as possible to the physiological events associated with them. However, research directly concerned with emotion has moved away from the classical model.
Modern approaches accept that emotion words are irreducibly complex. They refer to syndromes defined by clusters of elements that tend to co-occur. Unquestionably some of the elements are related to biology. However, others are dispositional - i.e. they relate to the sorts of things that people are likely to do in a given state; and others refer to particular social contexts. Attaching labels to particular combinations of elements allows people to predict, evaluate, and explain behaviour, their own and other people's.
PHYSTA is broadly aligned with the modern approach. That means that the project does not simply aim to attach analysable labels to extreme states which are regarded as psychologically simple. It is at least as much concerned with capturing some of the richness of the judgements that people can draw from evidence of emotionality in everyday states. That has implications for both the samples of emotional behaviour, and the assessments of them, that are to be incorporated in the training and test material.
1.2 Samples of emotional behaviour
One guiding principle is implicit in what has already been said. Training and test material should sample the wide range of behaviours in which emotion is a factor. Because PHYSTA has a view to practical applications, parts of the range which are reasonably common are of particular interest. The extreme cases which classical theory considers 'pure' emotion are of interest, but they are not indispensable, and should not be allowed to skew the whole enterprise.
Linked to that, material should be as real as possible. Research has often used actors, and that is difficult to avoid if the focus is on pure emotion, since there are obvious problems associated with recording genuine samples of extreme anger or grief. However, if we are interested in relatively common manifestations of emotionality, then there is less need and less justification for using actors.
1.3 Signal and interpretation streams
Training and test material needs to contain two streams. One simply describes visual and acoustic inputs. It will be called the signal stream. The other attaches emotional interpretations to episodes in the signal stream. It will be called the interpretation stream.
The signal stream itself subdivides. The basic part includes what is actually captured by cameras and microphones. That will be called the stimulus. Capturing suitable stimulus sequences is a major undertaking, and it is one of the key themes of this report. To the stimuli may be added descriptions which abstract relevant properties from the raw signals - call these processed signals. Suitable formats for a processed signal stream are discussed in another PHYSTA report.
The most obvious way of constructing an interpretation stream is simply to attach emotion labels (e.g. "anger", "pique", "relief") to episodes in the signal stream. However, that approach is not particularly satisfying, for a variety of reasons. Labelling in and of itself falls well short of the goal of predicting, evaluating, and explaining behaviour. There are also practical problems associated with the sheer diversity of labels that natural languages use to describe emotion-related states. The research reviewed in the previous report on emotion suggests a range of alternative approaches. One of the key challenges of the project is to find suitable ways of exploiting and developing those ideas.
1.4 Overview and state of progress
Although a certain amount of material is available, and can be used in early development of the PHYSTA system, it has become clear that the project needs to assemble its own database.
Progress has been made at several levels.
1. Concepts and principles relevant to the construction of an audiovisual emotion database have been set out. Perhaps surprisingly, this appears to be the first systematic attempt to set out such a framework.
2. Work has begun on two approaches to obtaining suitable stimuli. The BBC has been approached for permission to use appropriate kinds of broadcast material, and studio recordings have been made of arguments in which friends discuss emotive topics.
3. Work on the production of processed signals is described in another report.
4. Two approaches to constructing the interpretation stream have been piloted. A format has been developed in which participants in the studio recordings review the recordings and assess the genuineness of their own emotional involvement. A system ('Feeltrace') has also been developed which allows third parties to report continuously on the emotional character of stimulus events, and it has been piloted using the studio recordings.
2. PRE-EXISTING MATERIAL
This section reviews existing collections of material with at least some connection to the expression of emotion in human faces or vocal behaviour. The Web contains many sites that refer to research on topics related to emotion and facial and speech information. We concentrate on those that contain databases with at least some relevance to our goals, but note others to indicate that we have not simply overlooked them.
2.1 Sources dealing with the study of human emotion
Many links concerned with emotion refer to sites where research in Psychology is carried out. These sites (e.g. the UC Berkeley Psychophysiology Lab, the UC Santa Cruz Perceptual Science Lab, the Geneva Emotion Research Group) tend to deal with the expression of emotion and to describe research on the emotional state of human beings in different cognitive conditions. They give interesting details about the main outcomes and evidence of their experiments on emotional behaviour and detection of emotion by ear and eye, using speech and facial animation as inputs. They also provide rich bibliographic references. However, they tend not to make their stimulus sources publicly available.
Three sites are particularly relevant. An interesting overview of models and approaches used historically in this area of human psychology, as well as a list of related links, is available at the site of the Salk Institute for Biological Studies (La Jolla, California). Recent techniques for facial expression analysis and acoustical profiles in vocal emotion are published by the Geneva team. Some useful suggestions about stimuli to be used in order to get spontaneous emotions and how to elicit emotion in Lab setting are also available at the Berkeley site above.
On the other hand, most sites are involved in projects dealing with topics only indirectly related to emotion and audiovisual data characterised by emotion. They reflect the enormous amount of interest that has been stimulated by research on man-machine interaction, computer vision, medical applications, lipreading, videoconference, face synthesis and so on. Most of them refer to the theoretical basis of their approach or examine issues like relationships between facial expression ageing and attractiveness, trying to describe features which could lead a machine to detect cues about these human characteristics (see the links proposed by the UCSC Perceptual Science Lab). Emotional content of faces and voices is often an issue, but only a few of them choose this topic as the main target of their research.
A few make their stimuli freely available as databases. Video sequences containing facial expressions can be downloaded from various WWW sites as detailed below whereas speech materials tend to be more scarcely represented.
In the summary that follows, we try to give as much information as possible mainly about the ones showing interests related to our aims. More details about the material they contain, and the exact location where it is available, can be found in the appendix.
2.2. Faces: static images
Faces have been a focus of research in several disciplines, and databases which present pictures of them are offered by many labs all over the world. These collections could represent a source of test material, but they are not always emotionally expressive, or associated with suitable descriptors of emotional state.
2.2.1 Electronic collections
There are many collections of static pictures that show faces under systematically varied conditions of illumination, scale, and head orientation, but very few consider emotional variables systematically. There are examples which do portray emotion, but bringing together samples from various databases with non-uniform format is not an ideal procedure in terms of practicality or consistency.
Databases containing emotion-related material that are freely and immediately available include the following:
Yale http://cvc.yale.edu/projects/yalefaces/yalefaces.html
165 grayscale images (size 6.4MB) in GIF format of 15 individuals. There are 11 images per subject, one per different facial expression or configuration: centre-light, w/glasses, happy, left-light, w/no glasses, normal, right-light, sad, sleepy, surprised, and wink. The database is publicly available for non-commercial use.

Figure 1 Sample sequence from Yale database
Figure 1 shows a sample of a Yale sequence. It illustrates a recurring problem in the area. A suitable term for the images might be 'staged'. Expressions like these might be encountered in politics, storytelling, or the theatre, but intuition suggests that it would be very disturbing to encounter them during something that we regarded as a sincere interaction at home or at work.
Geneva http://www.unige.ch/fapse/emotion.html
Figure 2 shows a sample of expressions made available by the Geneva group. The contrast with Figure 1 is very striking: it is obvious that the pictures show people genuinely engaged in emotional behaviour. However, the available data set is small. The group report having records of elicited expressions, but there is no explicit intention to make them widely available.

Figure 2 Sample of expressions from Geneva database
ORL ftp://ftp.orl.co.uk:pub/data/
The ORL Database of Faces contains a set of face images taken between April 1992 and April 1994 at ORL. The database was used in the context of a face recognition project carried out in collaboration with the Speech, Vision and Robotics Group of the Cambridge University Engineering Department. There are ten different images of each of 40 distinct subjects. The images vary the lighting, facial details (glasses / no glasses), and aspects of facial expression which are at least broadly relevant to emotion - open / closed eyes, smiling / not smiling. All of the images were taken against a dark homogeneous background with the subjects in an upright, frontal position (with tolerance for some side movement).
The files are in PGM format, and can be viewed on UNIX systems using the 'xv' program. Each image is 92x112 pixels, with 256 grey levels per pixel. The database can be retrieved from ftp://ftp.orl.co.uk:pub/data/orl_faces.tar.Z as a 4.5Mbyte compressed tar file or from ftp://ftp.orl.co.uk:pub/data/orl_faces.zip as a ZIP file of similar size.
PICS database at Stirling http://pics.psych.stir.ac.uk/cgi-bin/PICS/pics.cgi
Another important collection of face images is available at the site of the PICS database at the University of Stirling, within a larger collection of various other images. Samples of face images are available in demo version. All the collections can be downloaded after registration as tar-compressed files. Among the most promising are those of a first database of 313 images where faces show three different expressions each (see Figure 3, examples 1a and 1b) and those of a second database of 493 images and two expressions per subject (see Figure 3, examples 2a and 2b). A third database is composed by 689 face images (see Figure 3, examples 3a and 3b) with four expressions represented. Minor sets are also available.
1a. 1b.
1b. 2a.
2a. 2b.
2b. 3a.
3a. 3b.
3b.
Figure 3 Samples of images from PICS database
The Appendix lists some other sites that present facial archives, but that contain either a limited amount of emotion-related material, or none.
2.2.2 Printed collections
The classic collection of photographs showing facial emotion was published by Ekman and Friesen. It is the natural reference source for computational research on static visual indicators of emotion, yet it appears not to be available in electronic form.
The PSL site lists various other historically significant collections of face images or illustrated studies of emotion expression e.g.
John Bulwer (1648), The Deafe,
Duchenne de Boulogne, C.-B. (1862) The Mechanism of Human Facial Expression,
Charles Darwin (1872) The Expression of the Emotions in Man and Animals,
Ermiane, R. (1949) Jeux Musculaires et Expressions du Visage,
Ermiane, R. & Gergerian, E. (1978) Album des expressions du visage,
An interesting modern addition - again not available in electronic form - is a collection of portraits that successfully convey the sitter's emotional state or disposition.
2.3. Faces: videos
Kinetic samples of faces are not so frequently encountered, and kinetic sequences which are emotionally characterised are even less common. Those which are available as freeware rarely exceed demonstrations with sequences of three or four frames.
The material that tends to be available at these sites consists of images produced by research software - e.g. for lip tracking or facial animation - instead of the original video sequences or images used for the analysis and/or the training.
An impressive list of projects carried out on these fields are given at the PSL site.
Samples of movies of faces expressing emotion are at the location:
http://www.cs.cmu.edu/afs/cs.cmu.edu/user/ytw/www/facial.html
where they are used to describe a few examples of the application of the optical flow technique for six primary emotions (surprise, joy, anger, disgust, fear, sadness).
Video sequences containing facial expressions can also be downloaded from the MIT Media Lab Perceptual Computing Group ftp server. The ftp site can be reached through the address:
ftp://whitechapel.media.mit.edu/pub/DFacs++/
and contains video sequences of approximately 10 frames per expression. Expressions covered are smile, anger, disgust, and surprised. At its present form, the database consists of expressions made by three persons only.
2.4 Speech
Corpus linguistics has been a major research area in the past decade, and it has produced a number of substantial speech databases, in a number of languages. Several of them include emotion-related material.
An Emotional Speech Database has been compiled for Danish (DES. See Engberg et al., 1997) but no details are yet available. A CD-ROM contains 48kHz sampled audio files and a phonotypical SAMPA transcription of 30 minutes of speech (involving two words (yes and no), nine sentences (four questions), and two passages) performed by four actors believed able to convey a number of emotions (Neutral, Surprise, Happiness, Sadness, Anger). It is available at the Center for Person Kommunikation of Aalborg.
Another corpus partially oriented to the analysis of emotional speech is the one called GRONINGEN (ELRA corpus S0020) which contains over 20 hours of Dutch read speech material from 238 speakers in 4 CD-ROMs. See appendix for details.
For English, a joint research project between The Speech Laboratory at the University of Reading and The Department of Psychology at the University of Leeds carried out the Emotion in Speech Project (see Greasley et al. 1995). Samples are organised in a database. It is scheduled to be released on CD-ROM, but is not available as yet.
Figure 4 shows an annotated sample from the Reading/Leeds project. A number of interesting points can be made about the format.
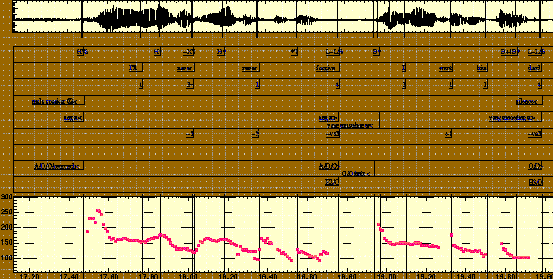
Figure 4: Annotated sample from the Reading/Leeds project
Text: “I’ll never never forgive. I want him dead.”
Speaker: Male
Emotions: Anger, vengeance.
In the processed signal stream, the team included prosodic features described using the standard ToBI system (Silverman et al, 1992). Although the result is included in the database, they conclude that it is too phonologically-oriented to permit detailed representation of the phonetic and paralinguistic information that is relevant to analysis of emotional speech. As a result they added descriptors based the prosodic and paralinguistic feature system devised by Crystal (1969).
In the interpretation stream, the team also found it necessary to go beyond the classification system that phoneticians generally use in describing the attitudes and emotions transmitted by vocal means. Both points are in line with conclusions drawn in our previous report.
One of the largest sources available is in fact the set of audio files collected by our own group in a study reported by McGilloway et al. (1995). It includes digitised recordings of 40 speakers reading passages constructed to suggest four emotions (fear, anger, sadness, and happiness) as well as a neutral passage. The passages contain 25-30s each. A second tier of files associates with each passage a summary of its features in what we call the augmented prosodic domain - these relate to prosody and some broad spectral characteristics.
2.5 Speech and Video
Material which combines speech and video is still rare. The point is underlined by a comment by the M2VTS group, who were concerned with multi-modal identification of faces. They were unable to find a database which could meet their requirements of synchronised speech and image, and the opportunity to extract 3-D face features from the database. As a result, they recorded their own. It is now one of two speech-plus-video databases (M2VTS and Tulips 1.0) that we have been able to trace. Neither of them seems to be emotionally characterised.
M2VTS http://www.tele.ucl.ac.be/M2VTS
M2VTS Multimodal face Database (Synchronised speech and image - see above). This is a substantial database combining face and voice features, contained on 3 High Density Exabyte tapes (5 Gbyte per tape). It claims to be the first multimodal face database available on the market. The images and sound it contains are intended for research purposes in the field of multimodal biometric person authentication.
It accounts for
37 different faces and provides 5 shots for each person taken at one week intervals or when drastic face changes occurred in the meantime. During each shot, people have been asked to count from '0' to '9' in their native language (most of the people are French speaking).The final format for the database is for images: 286x350 resolution, 25Hz frame frequency / progressive format, 4:2:2 colour components. Sound files (.raw) are encoded using raw data (no header). The format is 16 bit unsigned linear and the sampling frequency is 48kHz.
Extended M2VTS http://www.ee.surrey.ac.uk/Research/VSSP/xm2vtsdb/
An Extended M2VTS Multimodal Face Database also exists: it contains more than 1,000 GBytes of digital video sequences. It is not clear which are the languages represented. Speakers were asked to read three English sentences which were written on a board positioned just below the camera. The subjects were asked to read at their normal pace, to pause briefly at the end of each sentence and to read through the three sentences twice. Audio files of the three sentences, a total of 7080 files, are available on 4 CDROMS. The audio is stored in mono, 16bit, 32 kHz, PCM wave files.
Tulips 1.0 ftp://ergo.ucsd.edu/pub/
Tulips 1.0 is a small audiovisual database of 12 subjects saying the first 4 digits in English. Subjects are undergraduate students from the Cognitive Science Program at UCSD. The database contains both raw acoustic signal traces and cepstral processed files in PGM format at 30 frames.
Audio files are in .au format. The format of the .au files is as follows: The first 28 bytes in each file are reserved for header information, using the standard .au format.
Signal information starts on byte number 29 (byte 28 using zero-offset). Each byte encodes acoustic energy on each sample (1 byte per sample). The sampling rate is 11127 Hz. Video files are in .pgm format, 100x75 pixel 8bit gray level.
2.6 Overview
In view of the widespread attention that has been paid to the perception of emotion, it is somewhat surprising that suitable training and test material is not more widely available. Nevertheless, although a good deal of material exists which is relevant to emotion in a broad sense, most of it is quite limited in its nature. Some is not in machine-usable form, or is in machine-usable form but not readily accessible. What there is tends to be limited in the range of emotions that it provides, or in the information provided about the emotions, or in the number of subjects. The most marked limitation of all is in modality –very few sources include both voice and kinetic images of faces, and none of that material appears to be emotionally characterised.
As a result, existing material is of limited value to the PHYSTA project. What it offers is an interesting way of testing the system once it has been trained, and it suggests possible database formats. But for the bulk of training and testing, the project has no option but to create its own database. The following sections consider how that should be done.
3. OBTAINING STIMULUS SEQUENCES
Obtaining genuinely realistic speech data is well known as a difficult problem (Milroy 1980), and it is one in which PHYSTA team members have a long record of involvement (Douglas-Cowie 1978, Douglas-Cowie & Cowie 1998). The particular kinds of stimulus material that are relevant to this study pose special challenges.
There are various methods which seem to offer some prospect of success. This section tries to provide a taxonomy of the main options, noting their advantages and disadvantages. It is curious that despite the extensive literature on the expression of emotions, the issue seems not to have been set out systematically.
3.1 Context free simulations
This seems a suitable term for techniques in which a performer is asked to generate some kind of emotional behaviour more or less in a vacuum. Examples are posed photographs and emotionally ambiguous sentences spoken to convey a particular emotional expression.
Context free simulations have obvious attractions from an experimental point of view. They are easy to carry out, and they can provide material which is balanced with respect to potentially confounding variables. An equally obvious disadvantage is that the material is emphatically not natural. The disadvantage is multiplied if we want to consider the possibility that emotion may be signalled over time. Intuitively, it seems much easier to generate a snapshot or a short sentence in a simulated emotion than it is to sustain the performance over a substantial period - which is an interesting point in its own right.
3.2 Reading
Reading material with appropriate emotional content is a second convenient technique - using an autocue if audiovisual stimuli are needed.
Reading can produce speech that is convincingly emotional at a certain level. For instance, the McGilloway et al material was generated by subjects reading passages designed to elicit particular types of emotion. The passages were preselected for their effectiveness at inducing emotion, and succeeded to the extent that several readers were unable or unwilling to read the passages conveying sadness and fear, and informal evaluation suggested that most readers were caught up in the relevant emotions to at least a certain extent.
The obvious difficulty is that the reading task incorporates constraints that inevitably bias the sample obtained. Verbal content and phrasing either fail to reflect the emotion or else reflect the intuitions of the person who wrote the passage. In addition, the closer the written material is in style to spontaneous speech, the harder most people find it to read. Facial expression is directly constrained both by the reading task (because the eyes need to target the text) and by the need to keep speaking (so that gestures with the mouth are constrained).
3.3 Prompting
A step less constrained than reading is providing a strongly emotive prompt and inviting the subject to talk about it. Obvious types of prompt are highly charged stories, extracts from film or television, or pieces of music. The threat of having to speak in public has been used to induce apprehension. Various techniques using mental imagery have also been used to induce target emotional states (see EMOVOX research plan).
Prompt techniques relax some of the biases associated with reading, but (at least in the most straightforward form) they share some major constraints with it. First, the speech that they generate tends to be a set piece monologue. That is a possible form of emotional expression, but not the only one, and probably not a particularly common one. Second, prompts are a more natural way of inducing some emotion-related states (sadness, anger, disgust, amusement) than others (love, ecstasy, surprise).
3.4 Games
The Geneva group in particular have used interactive computer games to elicit genuine emotions (see e.g. Kaiser et al.1994, Kaiser et al.1998 ). For this purpose, they have developed an environment called the Geneva Appraisal Manipulation Environment. This is a tool for generating experimental computer games that suggest specific micro world scenarios. It allows automatic data recording and automatic questionnaires. While playing the experimental game, subjects are videotaped and these tape recordings allow an automatic analysis of the subject's facial behavior with the Facial Expression Analysis Tool (Kaiser & Wehrle, 1994). Facial actions and data are then categorized in terms of FACS (Ekman & Friesen, 1978) and can be automatically matched to the corresponding game data (using a time code as a reference for both kinds of data).

Figure 5: Examples from the Geneva project
Figure 5 shows examples of the facial expressions that they have generated.
The approach does seem capable of eliciting genuine emotion in a reasonably controlled way. However, it has various limitations. A minor one (which is noticeable in Figure 2) is that it constrains attention in a very distinctive way - subjects' gaze is generally focussed on the screen. The major limitation is that in the present state of the art, the technique elicits only facial expressions of emotion. That will change as voice input techniques for computers improve. In the interim apparent voice control could be achieved using "Wizard of Oz" techniques (these involve a hidden human controlling the computer that the subject believes he or she is interacting with). However, the technical problems would be very substantial.
3.5 Broadcasts
The Reading/Leeds project identified a large ready made source of emotional speech, in the form of unscripted discussions on radio (Greasley et al. 1995). For the audiovisual case, chat shows in particular provide a comparable source.
It would be naive to think that interactions in studio discussions were totally unaffected by the setting. The situation is inhibiting in some ways, and in others it invites dramatisation. Nevertheless, it seems very likely that this kind of source contains least some episodes which are closer to spontaneous expressions of quite strong emotions than the previous approaches are likely to elicit.
3.6 Social facilitation
Both game- and broadcast-based techniques take advantage of the fact that emotion has a strong communicative function, and interactive contexts tend to encourage its expression. That led us to explore the possibility of creating settings in which expressions of emotion were likely to occur naturally. Two levels were considered.
One is a variant on the prompt strategy, but with a skilled fieldworker trying to put the informant at ease and draw out emotional responses - to some extent, playing the role of the chat show host in broadcast material. The clear disadvantage is that the contribution of the fieldworker is large, and difficult to establish.
The second level removes that element of intervention by selecting small groups of people who know each other well enough to talk freely, and setting them to talk on a subject that is likely to evoke emotional reactions. That strategy has been piloted, and the results are considered in section 5.
3.7 Overview
Some approaches are more seriously artificial than others, and it is preferable to avoid them if possible. We have begun pilot work on the option that seems to be the least artificial, and hence the most satisfactory if it works as might be hoped.
On the other hand, there seems to be no perfect solution (within the limits of ethics and practicality). Partly that is because the expression of emotion seems prima facie to be quite context-dependent: it may take different forms in different settings. As a result, the best strategy is probably to use a variety of sources and try to distinguish common and situation-specific manifestations.
4. ASSIGNING INTERPRETATIONS
This section draws on background theory that was discussed in the previous PHYSTA report on emotion. It indicates how the ideas presented there might be translated into the design of an appropriate interpretation stream.
4.1 'Cause' and 'effect' interpretations
The terms 'cause' and 'effect' provide a concise way of drawing a basic distinction between types of interpretation. Essentially, 'cause' type interpretations describe (or purport to describe) the state which gave rise to an emotional episode, whereas 'effect' type interpretations describe (or purport to describe) the reaction that the episode elicits in an observer (or observers).
The fact that people are good at judging emotion means that the two will generally be closely related. However, there are cases where they diverge - such as deception, acting, and cases where observers find emotional signals equivocal.
The distinction has a major bearing on the issue of data collection. Requiring 'cause' type interpretations massively restricts the kinds stimulus sequence that can be used: it rules out material such as broadcasts where there is no access to the people who produced the emotion. However, it is not clear that cause type interpretations are a necessity. They become important if one is interested in developing a system that outperforms humans - for instance, a lie detector. That is only one conceivable application for an automatic emotion detection system, though.
On the other hand, it is clear that naive reliance on 'cause' type interpretations is to be avoided. In particular, the fact that a performance was produced by asking someone to portray a particular emotion does not mean that the result is a valid sample of that emotion.
The general position adopted here is that 'effect' type interpretations are mandatory. 'Cause' type interpretations are not, though they are certainly valuable if they are available.
4.2 Face validity
The most basic form of interpretation concerns validity. It is essential to know whether a stimulus sequence should be regarded as genuine or not. Badly simulated performances should not be used as a basis for training, unless there is a deliberate intention to create a system which recognises them as anomalous.
Following on from the previous point, two types of validity are relevant - whether the sequence truly reflected emotions in the person who produced it, and whether observers regard it as convincing. The two do not necessarily coincide.
Existing sources vary greatly in the level of validation that they describe. The Geneva group's research on faces describes very full 'cause' type validation, involving situations theoretically calculated to evoke particular emotions, and subjects rating their own emotional states (Kaiser et al.1998). That makes the invaluable point that subjects who show moderate surface reactions may actually be more strongly affected subjectively than subjects who show strong surface reactions. The Geneva group have also carried out 'effect' type validation of vocal behaviour, and examined the features associated with convincing and unconvincing portrayals of emotion (Johnstone et al.1995). At the other extreme, some sources make no mention of validation.
Again, it will be assumed that the 'effect' type criterion has priority, i.e. a convincing portrayal will be regarded as a legitimate source. As before, though, information about the producer's emotional state is valuable if it is available.
4.3 Categorical
The term 'categorical' is used to describe interpretations which identify emotional content by attaching everyday emotion terms to episodes in the signal stream.
Categorical descriptions are strongly associated with material that is elicited by simulations, reading, or prompting, simply because the performance usually starts from a categorical conception of the emotion that is to be produced.
As the Reading / Leeds team (http://midwich.reading.ac.uk/research/speechlab/emotion/) have pointed out, categorical descriptions become less satisfactory when the situation is less controlled. That tends to produce complex emotional episodes which are difficult to pin down without resorting to rather subtle terms (e.g. 'vengeful') and even combining them ('vengeful anger'). At that level of subtlety, different raters are liable to use different terms, and the problem of integrating the different categories becomes pressing. The only obvious solution is to move towards what is effectively a continuous representation, in which emotion terms are understood to be analysable in terms of proximity and location on dimensions such as strength, simplicity, etc..
4.4 Dimensional
Our previous report reviewed work which suggests that emotion judgements can be represented - at least to a useful approximation - as points in a space with a moderate number of dimensions. That idea opens possibilities which are potentially important for training and test procedures.
Integration Translating initially categorical descriptions into numerical form offers the possibility of assessing whether different categorical descriptions are essentially close, assessing a central point and spread, etc.
Dimensional interpretation Instead of translating initially categorical descriptions into numerical form, judges could be asked directly to record emotional interpretations of stimulus sequences in terms of relevant dimensions (such as the evaluation and activity dimensions used by Whissell (1989) or the angle and magnitude dimensions of Plutchik (1994)).
Continuous input If suitable devices can be found, there is the prospect of dimensional interpretations being recorded continuously over a period of time, so that the perceived temporal structure of emotional episodes can be recorded.
Correlation If the interpretation stream describes emotion in terms of continua, then correlation-like relationships between signal and interpretation streams can be explored.
These ideas led to the development of the "Feeltrace" system which is described in section 5.
4.5 World models
There are clear advantages to the use of spaces with a small number of dimensions, but they inevitably fail to reflect distinctions that people regard as important. For example, the evaluation and activity dimensions used by Whissell do not distinguish in a natural way between fear and anger - both are negative and (at least potentially) active. The difference lies in the nature of the action that is likely to be taken - fight in the case of anger, flight in the case of fear.
That kind of example illustrates a general problem, which is to find a framework that reflects some of the subtler distinctions among emotion words but retains real coherence (i.e. it is not simply a collection of discrete categories presented in unfamilar terms).
An approach which holds some promise is reviewed in our previous report. It reflects research suggesting that emotion judgements can be represented in terms of schema-like structures specifying the essentials of the situation as perceived by the person experiencing the emotion.
We have explored techniques which might allow emotion to be described systematically in those terms. Practically, they would involve presenting a rater with a series of scales and asking him or her to gauge where on each scales a particular episode would be located. The ratings would probably need to be made at quite widely spaced intervals - say for a passage that was judged to be relatively constant in its emotional tone.
An example of a possible format is given below. Its function is to describe the (presumed) world model of a person engaged in an emotional episode. It does that by picking out a small number of emotionally significant elements in the situation - the agent, a significant other, the environment, and the agent's potential actions - and highlighting a few broad aspects of each that are relevant to the emotion. Two entries would be made for each scale, one specifying whether the scale actually has much bearing on the particular emotion in question, the other specifying where on each relevant continuum the person locates the relevant features of the situation.
SELF
informed..............................................................................ignorant
powerful..............................................................................vulnerable
desirable..............................................................................undesirable
owed..................................................................................owing
FOCAL OTHER
powerful..............................................................................vulnerable
desirable..............................................................................undesirable
owed................................................................................…owing
benign..............................................................................…hostile
ENVIRONMENT
desirable..............................................................................undesirable
benign.............................................................................….hostile
improving............................................................................deteriorating
controllable..........................................................................uncontrollable
ACTION
inhibit.................................................................................intensify
physical...............................................................................mental
advance...............................................................................retreat
This kind of approach needs development before it can be used systematically. However, descriptions of this level could conceivably be available within the lifetime of the project.
4.6 Units of analysis
Finding suitable units of analysis is a non-trivial problem. It seems essential to acknowledge that multiple levels of structure may be relevant.
At one extreme, there are reasons to consider units such as a conversation, which are not only extended in time, but also involves more than one person. It seems very likely that an emotion such as relief would be hard to identify without previous evidence of concern or worry, and triumph would be easier to identify given evidence that there had been conflict with another party who was now downcast. "Feeltrace" type descriptions lend themselves to continuous description of a protracted episode.
At an intermediate level, statistical measures of speech need to be collected over a time period, and it is not clear how long it needs to be to produce reliable information. Experience in related areas (Douglas-Cowie & Cowie 1998) suggests that episodes of about ten seconds - which are roughly sentence-like - can be differentiated statistically.
At the other extreme, it is reasonable to pull out 'peak' episodes with a distinctly emotional character. Kaiser et al. (1998), for instance, consider facial expression in terms of episodes contained within 5-second windows. Vocal expression of some emotions at least may tend to be concentrated in brief exclamations.
Related to these points, it seems likely that peak expressiveness in face and voice will often occur successively rather than in parallel. In that case, recognising that episodes are linked is a key task.
The main implication for a database is that it should not be structured in a way that presupposes what the relevant units are. It should allow a flexible approach to unit formation.
4.7 Uniqueness and uncertainty
It is tempting to assume that 'good' data consists of episodes which have a definite emotional character. However, uncertainty is a salient feature of emotional life. Phrases such as "I don't know whether to laugh or cry" indicate that the person experiencing the emotion may be ambivalent. Shows like "Blind Date" regularly dramatise the fact that people may find it difficult to recognise emotions related to attraction or dislike in another person – often to the amusement of third parties, and the embarrassment of the participants.
Ideally, a database needs to be capable of reflecting at least the second kind of uncertainty. There are two obvious ways of doing that. One is to incorporate measures of confidence within a single stream of data. The other is to attach alternative interpretations to episodes which tend to elicit more than one type of reaction.
5. FORMATS UNDER DEVELOPMENT
5.1 Socially facilitated emotive exchanges
Following the "social facilitation" approach described in section 3.6, we arranged discussions among groups of friends on topics that they felt strongly about. Three discussions took place, each involving three people. Each lasted about an hour. The topics (chosen by the participants themselves) were religion, euthanasia, and communism. Discussions took place in a TV studio, allowing high quality recording. In each group two people at a time were filmed, giving close-up images of their faces side by side on blue background. The third (unfilmed) person was asked to mediate and encourage rather than take a full part.
A simple response format was developed so that after the sessions, participants could indicate their own level of involvement. Most of them reported a degree of artificiality at the start, but all of them reported that at various points they became caught up in the discussion to the extent that the setting was not an issue. Most of them also identified periods where they were emotionally very heated.
The immediate outcome of the exercise is a set of audio-visual samples from six individuals, containing periods of (rough) neutrality and periods of emotional engagement from each. They also provide material that can be used to evaluate measurement techniques (see section 5.3)
More generally, the exercise confirms that it is feasible to engage emotion in studio conditions which allow high quality recording. The next step is to investigate social facilitation techniques designed to elicit more specific types of emotion.
5.2 Feeltrace
Following the ideas outlined in section 4.4, a continuous input device has been developed for recording emotional interpretations. It has been named "Feeltrace".
Feeltrace exploits the two dimensions identified by Whissell, activation and evaluation. Users are asked to specify the emotional tenor of an interaction by moving a circle on a computer screen (using a mouse) so that it shows where on those two dimensions a target person falls at any given instant.
The Feeltrace display is designed to convey the basic idea of emotion as a point in a 2-D space and to supplement it with several other types of descriptor. For that reason, it incorporates several features which are meant to ensure that subjects understand what a pointer position means.
1. The main axes are marked and described, one (activation) running from very active to very passive; the other (evaluation) running from very positive to very negative.
2. The colour of the pointer is keyed to its position using a colour coding introduced by Plutchik, which subjects find reasonably intuitive. The cursor is green in positions corresponding to highly positive emotional states, and red in positions corresponding to highly negative emotional states; yellow in positions corresponding to highly active emotional states, and blue in positions corresponding to very inactive emotional states.
3. Selected terms from Whissell's list are presented at the point in the space where their reported co-ordinates indicate that they lie.
4. Each octant of the emotion space is labelled with a term describing the archetypal emotion associated with that region of the space.
5. The dimension of time is represented indirectly, by keeping the circles associated with recent mouse positions on screen, but having them shrink gradually (as if the pointer left a trail of diminishing circles behind it).
Figure 6 shows examples of the display that a subject using Feeltrace sees at a particular instant in each of two episodes - one chosen to show the negative/positive colour coding, the other to show the active / passive colour coding.
Figure 6: Displays from Feeltrace as seen by a user
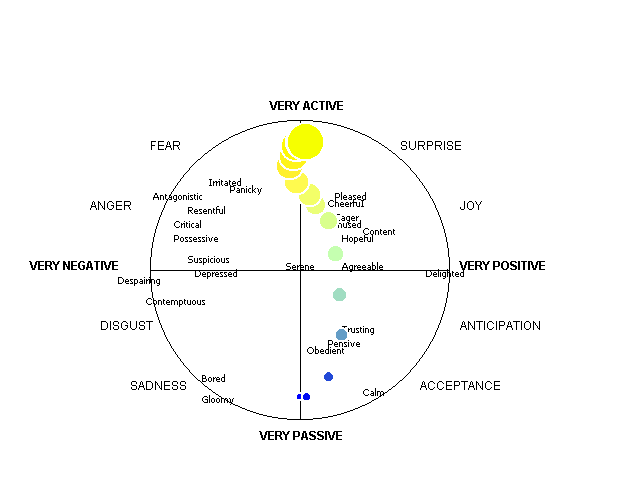
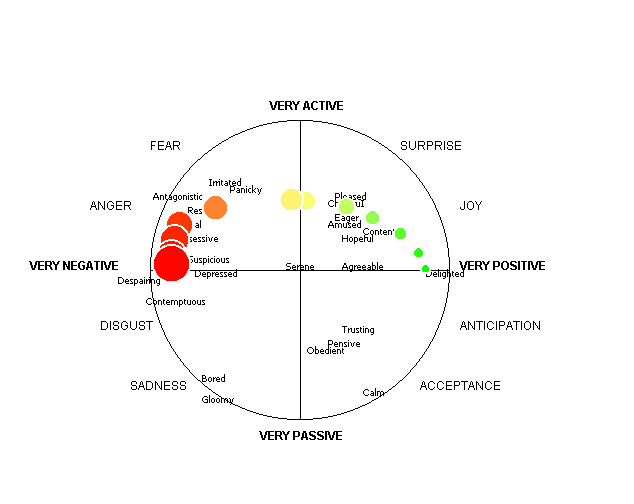 Subjects find the system reasonably easy to use, and it provides an intuitive impression of their broad feel for the emotional 'temperature' of the interchange, and the way it changes. Figure 7 shows results of applying the system to an extract from the tapes described in section 5.1 in an intuitively accessible format. The time axis is the straight diagonal line formed by black dots that runs from top left to bottom right. Mouse position at a given time is specified by the ‘ell’ that originates at the relevant dot on the time axis – activation is given by the vertical arm of the ‘ell’, and evaluation by the horizontal arm. Both arms are drawn in the colour associated with those vertical and horizontal connections. The outer ends of the ‘ells’ are marked by heavy dots and joined by thin black lines to provide a clearer impression of the way ratings move over time.
Subjects find the system reasonably easy to use, and it provides an intuitive impression of their broad feel for the emotional 'temperature' of the interchange, and the way it changes. Figure 7 shows results of applying the system to an extract from the tapes described in section 5.1 in an intuitively accessible format. The time axis is the straight diagonal line formed by black dots that runs from top left to bottom right. Mouse position at a given time is specified by the ‘ell’ that originates at the relevant dot on the time axis – activation is given by the vertical arm of the ‘ell’, and evaluation by the horizontal arm. Both arms are drawn in the colour associated with those vertical and horizontal connections. The outer ends of the ‘ells’ are marked by heavy dots and joined by thin black lines to provide a clearer impression of the way ratings move over time.
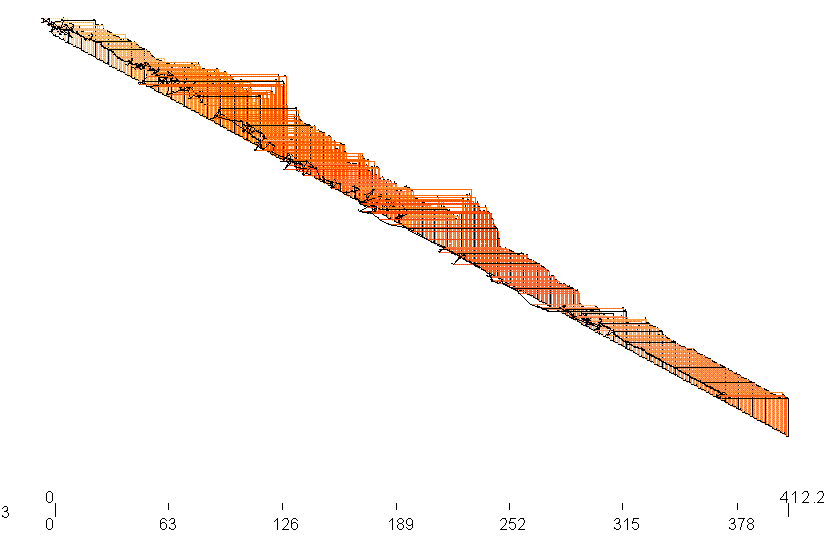
Figure 7: Illustration of Feeltrace output for an extended passage
5.3 Feeltrace applied to emotive exchanges: preliminary findings
A selected passage was examined in depth. Three subjects carried out Feeltrace ratings of a 7 minute extract from one of the exchanges - presented auditorily - whose emotional tone was predominantly within a single Feeltrace quadrant (negative and active). The unit of analysis was a turn (i.e. a passage where one subject spoke without interruption from others). Figure 8 shows average ratings for each turn, separating out the two main speakers. It is reasonably easy to see which ratings are for activation and which are for evaluation because the former are almost all positive and the latter are almost all negative. Clearly there is some broad consistency. Note that ratings are very reliably in the same quadrant, which is about the level of discrimination considered in traditional studies of emotion using categorical descriptions. There is also a considerable amount of agreement in about the rise and fall of emotional intensity within the quadrant. However, there are also divergences, and they clearly need to be taken into account.
An issue arising from the data is whether the representation in terms of activation and evaluation is necessarily the most useful. Data could be transformed into polar co-ordinates, after the pattern described by Plutchick. It seems possible that such a transformation would show a fair degree of consistency with respect to one measure (displacement from the centre), and much less with respect to the other (angle). The observation underlines the general point that representational issues need to be explored systematically rather than taken for granted.
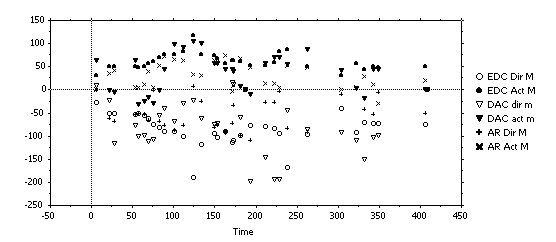
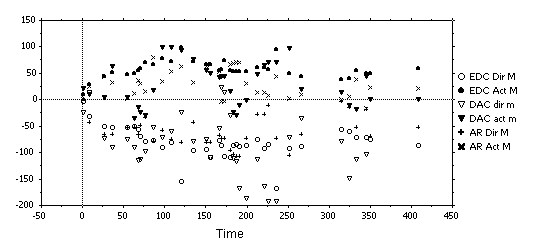
Figure 8: Feeltrace results in pilot study
Phonetic analysis focussed on 25 turns which provided contrasting, but reasonably consistent ratings. Prosodic features for each turn were measured using ASSESS and entered into a consolidated database. Each line referred to a turn. It began with identifying information – the time at which the turn began, the speaker, the text, and the name of the file holding ASSESS output. Summary Feeltrace ratings followed – mean and standard deviation for the turn, on each dimension, and for each rater. ASSESS prosodic measures were then listed. These measures were correlated with the Feeltrace ratings.
The prosodic measures correlated strongly with emotional tone, but not simply. Mean and standard deviation of pitch and intensity showed no reliable effects. The most general predictor was number of falling pitch movements per unit time, which correlates with increasing activation and negativeness. Other predictors were diagnostic for one speaker but not another - e.g. minimum pitch and number of inflections in the pitch contour per unit time. Others predict variability in judged emotionality, but not the direction of change. Others were salient for only one rater - e.g. one is strongly influenced by the upper limit of pitch, the others are not.
These findings give a preliminary sense of the kind of organisation and analysis that is to be anticipated in a full study of relations between signal and interpretation streams.
6. ARCHIVE FORMAT
Developing an appropriate archive involves balancing what is desirable from a theoretical point of view (which is generally the greatest possible naturalness) with what is tractable in machine terms (which generally favours maximum control over potentially complicating factors). This section outlines the kind of archive that is currently envisaged, and the issues that are to be resolved.
6.1 Core recordings
A core set of recordings based on traditional conceptions of emotion would provide a natural training set. It is an empirical question whether systems trained on such a set would generalise to situations involving more complex or less intense emotional variation.
The target would be to obtain a set of recordings of about 10 seconds each, showing about 50 subjects, each one exhibiting a specified range of emotions. The literature is not unanimous on a set of ‘primary’ emotions, but for a fair coverage of the range that tend to occur in everyday interaction, approximately the following range of emotions is probably needed:
The most naturalistic method that is likely to provide a sample of that kind is prompting.
6.2 Supplementary recordings
There are good reasons to collect more than the core sample outlined in 6.1. Key types of addition are
6.3 Recording
Analysis is much easier if ‘good’ recordings can be obtained, otherwise the level of preprocessing needed rises rapidly. Desirable features are:
- Full face images, with the face in a constant position.
- Studio lighting
- Professional quality film (i.e. M2, Betacam or equivalent)
Sound recording should use a microphone at a fixed distance from the speaker and a fixed recording level (i.e. sound levels should not be adjusted in the way a recording engineer would normally do).
The preliminary exercise (see 5.2) makes it very clear that these features impose a massive constraint on data collection. For instance, using studio lighting and professional video rather than VHS means that recording is tied to a studio rather than free to use readily available equipment. As a result, it needs to be clear how many of these features are absolutely necessary.
6.4 Digitisation
There is no agreed format for an audiovisual archive, but existing resources suggest parameter ranges. Tulips1.V and M2 VTS are useful points of reference. Experimentation is needed to identify the most suitable choice for our purposes.
For speech, M2 VTS uses a sampling frequency of 48kHz, whereas Tulips uses 11.127 kHz. Our own group has used intermediate sampling frequencies from 16KHz to 20kHz. Tulips1 contains the audio files in .au format, M2 VTS simply as integers. Proprietary formats make playback easier, but complicate analysis.
For video images, Tulips uses .pgm format 100x75 pixel 8bit gray level, 30Hz frame frequency; and M2 VTS uses 286x350 resolution, 25Hz frame frequency / progressive format, 4:2:2 colour components.
It is difficult to avoid dividing material into units of relatively standard length. The natural unit is probably a passage corresponding roughly to a sentence (which is also often a turn in dialogue). A facial gesture which overlapped a speech unit would be grouped with it: one which was not associated with an utterance would form a separate unit.
6.5 Continuous descriptors
A key type of intermediate representation involves a relatively small number of parameters plotted against a continuous time axis. These representations need to be computed, and it is rational to store them as part of the archive. They include (or might include)
6.6 Unit summary files
The role of roughly sentence-sized units was noted in 6.4. Various descriptors are naturally associated with that kind of unit, notably
In the pilot study of emotive exchanges, it became apparent that a file which assembled information about units of this level, including time of onset, provided a useful overall framework from which reference could be made to files giving more local detail.
7. CONCLUSION
A substantial effort has gone into defining the kind of test and training material that is appropriate for the PHYSTA project. The general approach may well be of wider interest, and we believe that if the material is collected and organised in a way that is clearly rational, it will be a significant resource for other groups as well as our own.
APPENDIX
This appendix organises sites into three categories:
[1] Sites where databases are available and accessible;
[2] Sites of other databases;
[3]Sites or personal home pages where relevant research on emotion, speech and facial expression is documented but there is no database.
[1] Sites where databases are available and accessible
CMU http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-8/faceimages/faces
Faces database of 20 subjects and 96 faces each. Four expressions (angry, happy, neutral, sad), four orientations (straight, up, right, left), with/without sunglasses in .pgm format.
CMU http://www.ius.cs.cmu.edu/IUS/har1/har/usr0/har/faces/test
About 700 images provided in aid evaluating systems developed for face detection.
Data Formats. Frontal views of faces in scenes, so the list of faces includes mainly those faces looking towards the camera; extreme side views are ignored.
The list of faces to detect are in a file with the following format (one line per face to be detected): filename left-eye right-eye nose left-corner-mouth center-mouth right-corner-mouth. The images are all in Compuserve GIF format, and are grayscale. A tar file containing all the images is also available.
CMU http://www.cs.cmu.edu/afs/cs.cmu.edu/user/ytw/www/facial.html
Only six video samples about six different facial expressions (anger, sadness, surprise, joy, fear and disgust) of one subject described by the optical flow technique (six grayscale mpeg movies).
Yale http://cvc.yale.edu/projects/yalefaces/yalefaces.html
The Yale Face Database (size 6.4MB) contains 165 grayscale images in GIF format of 15 individuals. There are 11 images per subject, one per different facial expression or configuration: center-light, w/glasses, happy, left-light, w/no glasses, normal, right-light, sad, sleepy, surprised, and wink. The database is publically available for non-commercial use.
ORL ftp://ftp.orl.co.uk:pub/data/
The ORL Database of faces. 10 PGM images of 40 subjects with different facial expressions. There are ten different images of each of 40 distinct subjects. For some subjects, the images are taken at different times, varying the lighting, facial expressions (open / closed eyes, smiling / not smiling) and facial details (glasses / no glasses). All the images are taken against a dark homogeneous background with the subjects in an upright, frontal position (with tolerance for some side movement). The size of each image is 92x112 pixels, with 256 grey levels per pixel.
image number for that subject (between 1 and 10).
The database can be retrieved from
ftp://ftp.orl.co.uk:pub/data/orl_faces.tar.Z as a 4.5Mbyte compressed tar file or from
ftp://ftp.orl.co.uk:pub/data/orl_faces.zip as a ZIP file of similar size.
PICS database at Stirling http://pics.psych.stir.ac.uk/cgi-bin/PICS/pics.cgi
Collection of different image types (PICS database). Various sets of faces are available in demo version but all the collections are entirely downloadable after registration as tar-compressed files. A first database of 313 images contains faces with three different expressions each and a second database of 493 images two expressions per subject. A third database is composed by 689 face images with four expressions represented. Minor sets are also available.
Tulips 1.0 ftp://ergo.ucsd.edu/pub/
Tulips 1.0 is a small Audiovisual database of 12 subjects saying the first 4 digits in English. Subjects are undergraduate students from the Cognitive Science Program at UCSD. The database was compiled at Javier R. Movellan's laboratory at the Department of Cognitive Science, UCSD.
Tulips1.A/raw contains the audio files in .au format. The sampling rate is 11127 Hz.
Tulips1.V contains the video files in .pgm format 100x75 pixel 8bit gray level. Each frame corresponds to 1/30 of a second.
M2VTS http://www.tele.ucl.ac.be/M2VTS
M2VTS Multimodal face Database (Synchronised speech and image - see above). This is a substantial database combining face and voice features, contained on 3 High Density Exabyte tapes (5 Gbyte per tape). 37 different faces 5 shots for each person counting from '0' to '9' in his/her native language (most of the people are French speaking). The final format for the database is for images: 286x350 resolution, 25Hz frame frequency / progressive format, 4:2:2 colour components. Sound files (.raw) are encoded using raw data (no header). The format is 16 bit unsigned linear and the sampling frequency is 48kHz.
Extended M2VTS http://www.ee.surrey.ac.uk/Research/VSSP/xm2vtsdb/
An Extended M2VTS Multimodal Face Database also exists: more than 1,000 GBytes of digital video sequences. It is not clear which are the languages represented. In its short description is only detailed that speakers were asked to read three English sentences which were written on a board positioned just below the camera. The subjects were asked to read at their normal pace, to pause briefly at the end of each sentence and to read through the three sentences twice. The three sentences audio files, a total of 7080 files, are available on 4 CDROMS. The audio is stored in mono, 16bit, 32 kHz, PCM wave files.
3D-RMA Face database http://www.sic.rma.ac.be/~beumier/DB/3d_rma.html
The 3D-RMA Database is available and easy accessible. This face database is dedicated to the analysis of real 3D features (structured light - 120 persons). 120 persons were asked to pose twice in front of the system. For each session, 3 shots were recorded with different orientation of the head: straight forward / Left or Right / Upward or downard. Each 3D file is organized as a set of 3D points along stripes.
M2VTS Multimodal face Database for sale, see following pages.
Synchronised speech and image.
GRONINGEN http://icp.grenet.fr/ELRA
ELRA corpus S0020 available in 4 CD-ROMs containing over 20 hours of speech from 238 speakers. It is a corpus of read speech material in Dutch, recorded on PCM tape.
Texts: 2 short texts (the famous North wind text, and a longer text, "de Koning" by Godfried Bomans, with many quoted sentences to elicit emotional speech); 23 short sentences (containing all possible vowels and all possible consonants and consonant clusters in Dutch); 20 numbers (the numbers 0-9 and the tens from 10-100), 16 monosyllabic words (containing all possible vowels in Dutch), and 3 long vowels (a:,/E:, \i:). Ninety-four of the 238 speakers also read an extended word list. In addition to the speech signal, an electro-glottograph signal has been included on the CD-ROMs.
[2] Sites of other databases
The Emotion in Speech Project http://midwich.reading.ac.uk/research/speechlab/emotion/
See main text for details
EMOVOX http://www.unige.ch/fapse/emotion/project.html
The EMOVOX project database, containing samples of voice varaibility related to speaker-emotional state, will be distributed on CD-ROM, and possibly on the Internet, to be used for bench marking future Automatic Speaker Verification systems with respect to their robustness against speaker state variation.
Not yet avalaible.
DES no web site
The Danish Emotional Speech Database
DES CD-ROM containing 48kHz sampled audio files and a phonotypical SAMPA transcription 30 minutes of speech (involving two words (yes and no), nine sentences (four questions), and two passages) performed by four actors believed able to convey a number of emotions (Neutral, Surprise, Happiness, Sadness, Anger). It can be acquired for a minimal handling and postage fee by contacting the Center for Person Kommunikation of Aalborg.
Not available on the Web.
ICV http://www.icv.ac.il
The face database FaceBase at the Weizmann institute of the Israeli Computer Vision is no longer accessible by anonymous ftp.
Imperial College ftp://sunsite.doc.ic.ac.uk/
Unable to find the right directory where faces are.
MIT ftp://whitechapel.media.mit.edu/pub/
Face images related to expressions of smile, anger, disgust, and surprise.
MIT ftp://whitechapel.media.mit.edu/pub/images/
Faces of 16 people, 27 of each person under various conditions of illumination, scale, and head orientation. Files tar.Z-compressed.
Stirling http://pics.psych.stir.ac.uk/cgi-bin/PICS/pics.cgi
Searchable Database. Not tested
The Face Recognition Home Page http://www.cs.rug.nl/~peterkr/FACE/face.html
Useful links to facial related topic.
UMIST http://images.ee.umist.ac.uk/danny/database.html
The UMIST Face Database consists of 564 images of 20 people. Each covering a range of poses from profile to frontal views. Subjects cover a range of race/sex/appearance. Each subject exists in their own directory labelled 1a, 1b, ... 1t and images are numbered consequetively as they were taken. The files are all in PGM format, approximately 220 x 220 pixels in 256 shades of grey. Pre-cropped versions of the images may be made available by contacting Daniel Graham. See Conditions of avalaibility at the above URL.
Other links to Face Databases not accessible:
Usenix face database ftp://doc.ic.ac.uk/faces/
Shimon Edelman's face database ftp://doc.ic.ac.uk/faces/
Univ. of Essex face database http://hp1.essex.ac.uk/projects/vision/allfaces/
University of Bern face database ftp://iamftp.unibe.ch/pub/Images/FaceImages/
Leiden University 19th century portrait database http://ind156b.wi.leidenuniv.nl:8086/intro.html
[3] Sites or Personal Home Pages where relevant research on emotion, speech and facial expression is documented but there is no database
Lallouache at ICP http://ophale.icp.grenet.fr/
Lipreading
Cyberware http://www.cyberware.com
Image collection. Demos and samples for faces.
Bhatia & Vannier http://www.ncsa.uiuc.edu/SDG/DigitalGallery/FACE.html
face images for medical applications
Petajan http://www.lucent.com/work/family/docs/petajan.html
face features analysis
Wiskott at Salk http://www.cnl.salk.edu/~wiskott/index.html
personal home page related to emotion analysis
Univ. of St. Andrews Perception Lab
http://psych.st-and.ac.uk:8080/research/perception_lab
Face images for research on ageing and attractiveness
FACE-IT at Pavia http://gracco.irmkant.rm.cnr.it/luigi/lupa_face.html
Images by synthesis
FaceIt at The Rockefeller Univ. Comput.al Neurosc. Lab http://venezia.rockefeller.edu/
Face local feature analysis
Applied Cognitive Res., Dresden http://physik.phy.tu-dresden.de/psycho/boris.html
Studies on vision and man-machine interaction
Waters http://www.crl.research.digital.com/projects/facial/facial.html
Terzopoulos http://cs.toronto.edu/~dt
Apple ATG http://www.research.apple.com
Stork http://www.cs.indiana.edu:800/finger/gateway?stork@crc.ricoh.com
NTT http://www.cs.indiana.edu:800/finger/gateway?pentland@mit.edu
Bregler http://www.cs.berkeley.edu/~bregler/
Beymer http://HTTP.CS.Berkeley.EDU/~beymer/
Luettin http://herens.idiap.ch/~luettin/
UMD Computer Vision Laboratory http://www.cfar.umd.edu/cvl/
Debevec http://www.cs.berkeley.edu/~debevec/face_recognition.html
Rubin/Bateson at Haskins http://www.haskins.yale.edu/haskins/heads.html
Massaro http://mambo.ucsc.edu:80/avsp99/
http://imsc.usc.edu/Events/workshops/mmsp98/
http://www.interface.digital.com/
More
(from the Emotion Home Page)Cacioppo John http://www.cog.ohio-state.edu/homepage/cfaculty/cacioppo.html
http://www.acs.ohio-state.edu/units/psych/s-psych/jtc.html (Ohio St. Univ.)
Canamero Dolores (IIIA-CSIC, Spain) http://www.iiia.csic.es/~lola
Cottrell Gary (U.C.S.D) http://www-cse.ucsd.edu/users/gary/
Damasio Antonio (University of Iowa)
http://www.vh.org/Welcome/UIHC/UIHCPhysDirectory/NeurologyMDs/DamasioA.html
Davidson Richard J. (Univ. Wisconsin, Madision)
http://www.neuroscience.wisc.edu/faculty/davidson.html
Ekman Paul http://mambo.ucsc.edu/psl/joehager/pekm.html
http://mambo.ucsc.edu/psl/ekman.html (U.C.S.F.)
Elliott, Clark (DePaul Univ.) http://condor.depaul.edu/~elliott/
Frijda Nico (U.V.A. The Netherlands)
http://Info.psy.uva.nl/Psychonomie/MEDEWERKERS/frijda
Kappas Arvid (Laval University, PQ, Canada)
http://www.psy.ulaval.ca/~arvid/Arvid1e.html
Koob George F. (Salk Institute)
http://www.cnl.salk.edu/NeuroWeb/department/faculty/koob.html
LeDoux Joseph E. (N.Y.U.)
http://www.cns.nyu.edu/corefacultyb.html#Joseph E. LeDoux
Manteuffel G. (Univ. of Bremen, Germany)
http://alpha.fbn.uni-rostock.de/fb5/gman/gman.htm
Mathews Andrew (Cambridge Univ., U.K.) http://www.mrc-apu.cam.ac.uk/
McGaugh J.L. (U.C. Irvine) http://www.bio.uci.edu:80/units/psych/faculty/mcgaugh.html
Miller G. (Univ Illinois, UC) http://www.beckman.uiuc.edu/groups/CNS/people/Miller.html
Petta Paolo (Austrian Research Institute for AI) http://www.ai.univie.ac.at/oefai/agents
Phaf, Hans (U.V.A. The Netherlands) http://Info.psy.uva.nl/Psychonomie/MEDEWERKERS/phaf
Picard Rosalind W. (M.I.T.)
http://www-white.media.mit.edu/vismod/people/faculty/picard.html
Rosenberg E.L. (Univ. California Davis) http://www.udel.edu/psych/fingerle/ERIKA.HTM
Servan-Schreiber David (Univ. of Pittsburgh) http://dss.psychiatry.pitt.edu/
Sloman Aaron (Univ. of Birmingham, U.K.) http://www.cs.bham.ac.uk/~axs/
Swanson Larry (U.S.C) http://www.usc.edu/dept/nbio/neuro/faculty/swanson.html
...